This article was originally published on Medium
The tf.data pipeline is now the gold standard for building an efficient data pipeline for machine learning applications with TensorFlow. For applications requiring tremendous quantities of training samples such as deep learning, it is often the case that the training data simply cannot fit in memory. In such cases, recourse to generators appears as a natural solution.
This post tries to answer the following question: how can one use the new tf.data.Dataset objects as generators for the training of a machine learning model, with parallelized processing?
Why this isn’t so obvious
This question may seem trivial, given that the tf.data pipeline offers a .from_generator() method, which in theory allows to transform any kind of generator into a streamable tf.data.Dataset object. The main issue arises from the fact that today, this .from_generator() method does not allow parallelization of the processing, if for instance a heavy data processing is performed within your generator. This is problematic if you already had a generator which performed heavy data processing with multiprocessing capability, such as a tf.keras.utils.Sequence object.
The tf.keras.utils.Sequence generator
At Scortex, for streaming large quantities of data during the training our deep learning models, we were using tf.keras.utils.Sequence objects as generators. An elegant implementation can be found in this blog post. However, Sequence objects may be subject to deadlocks when using multiprocessing, and are officially not recommended anymore by TensorFlow. Another drawback from using these kind of generators is that their implementation is crafty, which may require reworking them, for instance if you need to work with a custom steps_train when fitting your model with Keras.
The natural way
As stated above, the tf.data pipeline offers a .from_generator() method, which takes a generator as an input. Unfortunately, this method does not allow multiprocessing of the data generation (as of September 2021).
Instead, the “natural” way would be to start from a light generator (which only generates, for example, your metadata before any data processing), convert it to a Dataset object via the .from_generator() method, before applying a .map() with your heavy processing function as the main argument. Since .map() supports multiprocessing via the num_parallel_calls optional argument, this should work.
However, the processing function passed to the .map() method requires to be encapsulated in a tf.py_function. This is problematic if you work with data with exotic types to store your labels (such a mix of strings, dictionaries, lists, etc.), because tf.py_function only works with tf.Tensor objects, which must be of fixed types (usually either string, integers, or floats). One could think of serializing the data to a single type (like strings), but there is an easier way.
The easy way: writing a tf.data.Dataset generator with parallelized processing
The easy way is to follow the “natural” way, i.e. using a light generator followed by a heavy parallelized mapping. Only with an additional trick to solve the tf.py_function problem.
Let’s say you already have a training_set list, which is a list which contains the integrality of your non-processed data. The trick is to use a generator which will only generate the indexes of your training set. Each called training index will be passed to the wrapped py_function, which can in return evaluate your original dataset at that index. You can then process your datapoint and return your processed data to the rest of your tf.data pipeline.
def func(i):
i = i.numpy() # Decoding from the EagerTensor object
x, y = your_processing_function(training_set[i])
return x, y
z = list(range(len(training_set))) # The index generator
dataset = `tf.data.Dataset`.from_generator(lambda: z, tf.uint8)
dataset = dataset.map(lambda i: `tf.py_function`(func=func,
inp=[i],
Tout=[tf.uint8,
tf.float32]
),
num_parallel_calls=tf.data.AUTOTUNE)
Passing tf.data.AUTOTUNE to the num_parallel_calls argument allows TensorFlow to automatically determine the optimal number of workers for parallelizing the mapped function, but you could also hardcode any value you want. The rest of your pipeline can be standard:
z = list(range(len(training_set)))
dataset = `tf.data.Dataset`.from_generator(lambda: z, tf.uint8)
dataset = dataset.shuffle(buffer_size=len(z), seed=0,
reshuffle_each_iteration=True)
dataset = dataset.map(lambda i: `tf.py_function`(func=func,
inp=[i],
Tout=[tf.uint8,
tf.float32]
),
num_parallel_calls=tf.data.AUTOTUNE)
dataset = dataset.batch(8).map(_fixup_shape)
dataset = dataset.prefetch(tf.data.AUTOTUNE)
model.fit(dataset,
steps_per_epoch=steps_train,
epochs=epochs)
Note that if you feed your tf.data.Dataset to a Keras model, you don’t need to add a dataset = dataset.repeat() line at the end of your pipeline (Keras automatically repeats the dataset for you when the data is exhausted).
An additional note on batching
Note that you may need to add the following mapping right after batching, since in some cases (depending on the layers used in the trained model and your version of TensorFlow) the implicit inferring of the shapes of the output Tensors can fail due to the use of .from_generator():
dataset = dataset.batch(8)
def _fixup_shape(x, y):
x.set_shape([None, None, None, nb_channels]) # n, h, w, c
y.set_shape([None, nb_classes]) # n, nb_classes
return x, y
dataset = dataset.map(_fixup_shape)
Profiling tf.data.Dataset
We compare the two pipelines tf.keras.utils.Sequence and tf.data.Dataset, both with parallelization (workers is set to 12 in both cases, which corresponds to the number of cores available on the machine), on a highly input-bound training (heavy processing). Profiling is performed using the profile_batch argument in a TensorBoard callback.
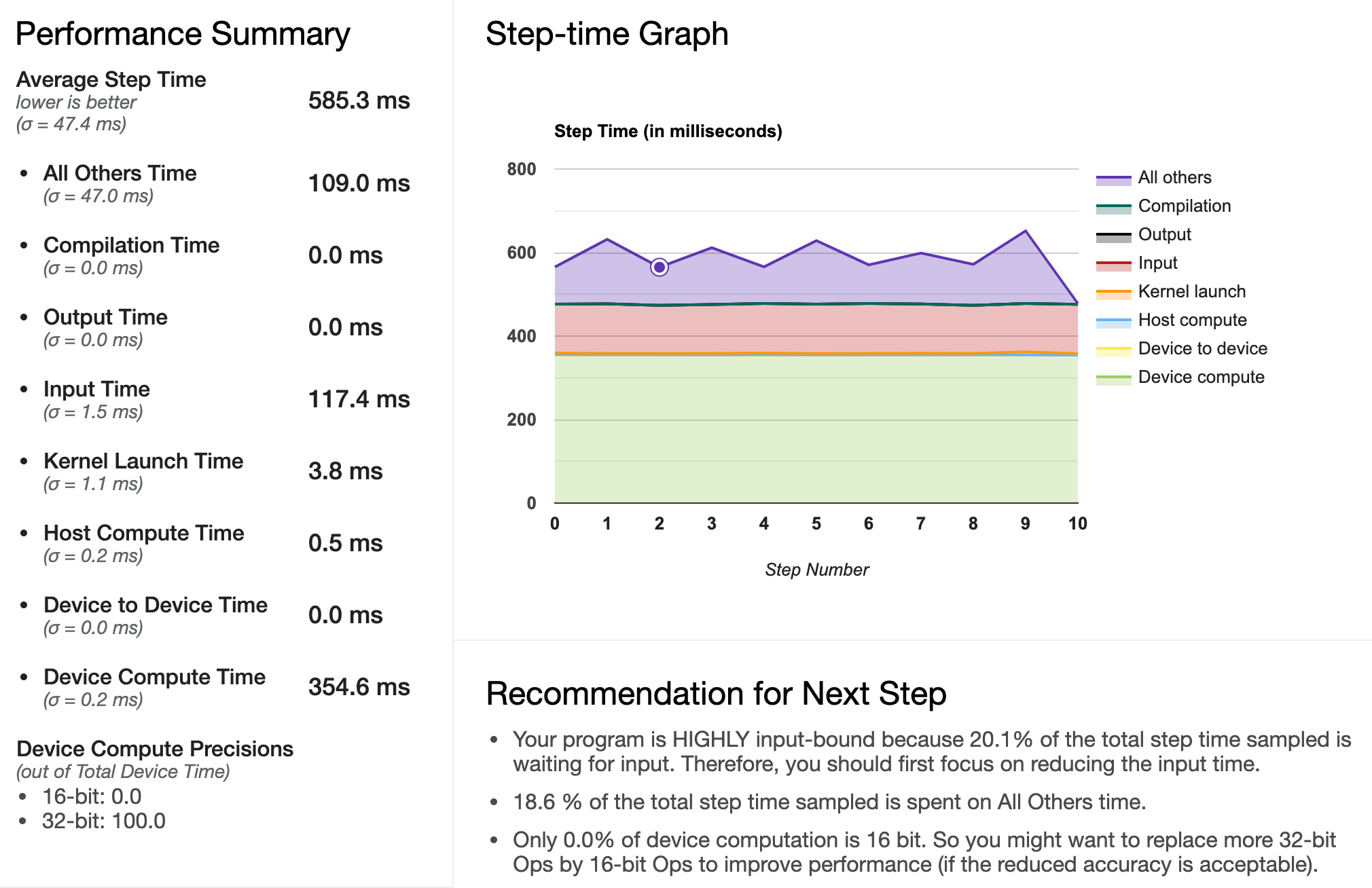
tf.keras.utils.Sequence pipeline
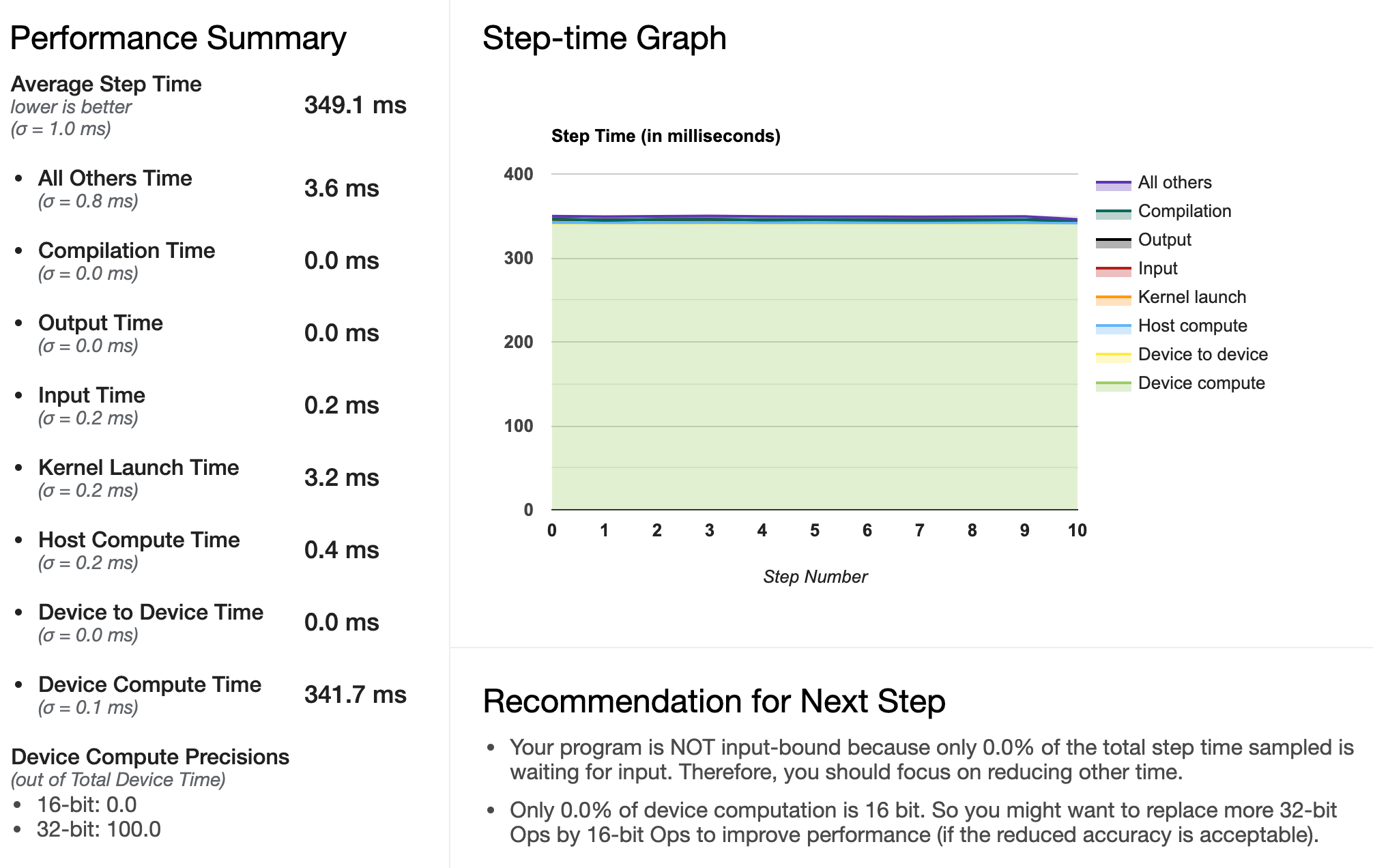
tf.data.Dataset pipeline
Using tf.data.Dataset, we notice an improvement of our pipeline: most time is now spent on the GPU, whereas before, the GPU was frequently waiting for the input to be processed by the CPU. A speed-up of more than a 1.5 factor can be observed in this particular case (this will of course depend on the nature of the processing and of the trained model). We suspect that this is because the pre-fetching of the batches is performed more continuously with tf.data.Dataset. This r/tensorflow answer is coherent with our observations (data not shown).
Conclusion
We successfully migrated our tf.keras.utils.Sequence data generator to a more up-to-date tf.data.Dataset one.
Read more tech blog articles on Machine Learning at Scortex: scortex.io/blog.